오늘은 다양한 신경망에 대해 배워보겠다.
다양한 신경망에서는 이미지 처리와 자연어 처리에 대해서 배울 것이다.
첫 번째로 이미지 처리를 위한 데이터 전 처리에 대해 배워보겠다.

우리 주변에는 위와 같은 이미지 처리 기술들이 있다.
이 기술들안에 딥러닝 기술이 포함되어 있다.

위와 같이 고양이 사진을 받아서 이것이 고양이인지 분류를 하기 위해서는 이미지를 모델에 입력을 해야한다. 그런데 우리는 그동안 잘 정리되어있는 정형 데이터만 DataFrame의 형태로 입력을 해왔다.
하지만 이미지는 DataFrame의 형태가 아니다.
그래서 먼저 이미지를 어떻게 데이터로 사용할 수 있는지 알아보겠다.
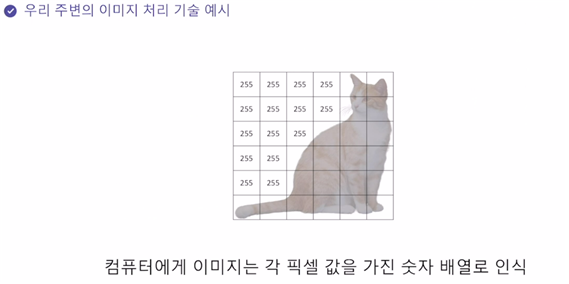
컴퓨터는 위와 같이 이미지를 픽셀 값을 가진 숫자 배열로 인식한다.
(네모 한칸이 픽셀이다. 값은 픽셀을 채워주는 색깔의 값이다.)

이제 이 이미지 데이터를 가지고 전 처리를 해야한다.
이미지 전 처리에서 가장 중요한 것은 모두 같은 크기를 갖는 이미지로 통일하는 것이다.
이 이미지를 통일할 때는 대표적으로 두 가지가 있는데 해상도를 통일하는 것, 색 표현 방식을 통일하는 것이다.
MNIST 데이터는 사람의 손글씨를 이미지 데이터로 표현한 것을 말한다.
해상도가 28×28이고 색 표현 방식은 Gray-scale로 원본데이터로부터 데이터들을 통일시켜준다.

위와 같은 표현이 해상도 표현이다. 1280×720은 가로 1280픽셀 곱하기 세로 720픽셀이라는 뜻이다.
실습 예제 1 : MNIST 분류 CNN모델 – 데이터 전 처리)
신경망을 이용한 학습을 시작할 때 대부분 MNIST를 접하게 된다. MNIST는 손글씨로 된 사진을 모아 둔 데이터이다.
손으로 쓴 0부터 9까지의 글자들이 있고, 이 데이터를 사용해서 신경망을 학습시키고, 학습 결과가 손글씨를 인식할 수 있는지 검증한다.

이미지 데이터를 출력하고 그 형태를 확인하여 CNN 모델에 적용할 수 있도록 데이터 전 처리를 수행하라.
CNN을 위한 데이터 전처리 :
MNIST 데이터는 이미지 데이터이지만 가로 길이와 세로 길이만 존재하는 2차원 데이터이다. CNN 모델은 채널(RGB 혹은 흑백)까지 고려한 3차원 데이터를 입력으로 받기에 채널 차원을 추가해 데이터의 모양(shape)을 바꿔준다. 결과는 아래와 같다.
[데이터 수, 가로 길이, 세로 길이]
-> [데이터 수, 가로 길이, 세로 길이, 채널 수]
● 차원 추가 함수
tf.expand_dims(data, axis)Tensor 배열 데이터에서 마지막 축(axis)에 해당하는 곳에 차원 하나를 추가할 수 있는 코드이다. (axis에 -1을 넣으면 어떤 data가 들어오던 마지막 축의 index를 의미한다.)
학습용 및 평가용 데이터를 CNN 모델의 입력으로 사용할 수 있도록 (샘플개수, 가로픽셀, 세로픽셀, 1) 형태로 변환하라.
tf.expand_dims() 함수를 활용하여 train_images, test_images 데이터의 형태를 변환하고 각각 train_images, test_images에 저장하라.
답 :

실행 결과 :

이제 이미지 처리를 위한 딥러닝 모델에 대해 배워보겠다.

우선 기존 다층 퍼셉트론 기반 신경망에서 이미지 처리가 어떻게 되는지 알아보겠다.
위와 같은 고양이 사진이 신경망의 입력으로 들어온다고 할 때 이 이미지는 배열로 정리된다.
근데 이 배열은 2차원 데이터이기 때문에 신경망의 입력으로 사용될 수 없다.
그래서 1차원 데이터로 정리를 해줘야한다.
각각의 행에서 빼서 차례대로 1차원 배열에 순서대로 넣는 방식으로 정리할 수 있다.
하지만 이런 방식이라면 6×6 픽셀의 사진 데이터를 입력 받기 위해서는 36개의 입력을 받아야한다. 이 경우 극도로 많은 수의 파라미터가 필요하다. 그리고 그냥 한줄로 나열하는 것이기 때문에 사진의 특징들이 바뀔 수 있다.
또한 위에서 오른쪽의 이미지도 고양이이다. 하지만 데이터의 관점에서는 이는 완전히 새로운 이미지 데이터이다. 이렇게 이미지에 조금만 변화가 있어도 그것들의 적용은 쉽지 않다.
따라서 정리하면 기존 다층 퍼셉트론 기반 신경망으로도 이미지를 분류할 수 있긴 하지만 정말 많은 파라미터가 필요할 수 있고 이미지 변화에 따라서 데이터 변화가 너무 심하기 때문에 기존 다층 퍼셉트론 기반 신경망은 성능이 많이 떨어질 수 있다.

이걸 해결할 수 있는 방법으로 나온 것이 바로 합성곱 신경망(CNN)이다.
이 CNN은 작은 필터를 순환시키고 이미지의 패턴이 아니라 특징을 중점으로 인식한다.
(ex. 귀가 있는지 없는지, 수염이 있는지 없는지)

그럼 합성곱의 구조를 보겠다.
위의 그림을 보면 Convolution Layer와 Pooling Layer가 있는 CNN 구조가 앞에 나오고 그 뒤에 Fully-Connected Layer(FC)로 이루어져있다.
이 CNN은 입력 이미지의 특징을 추출하게 된다. 그리고 FC가 분류를 수행하게 된다. FC는 지금까지 우리가 사용한 딥러닝 모델이라고 생각하면 된다.(노드들이 모두 연결되어있어서 Fully-Connected라고 한다.)

이제 조금 더 자세하게 Convolution Layer와 Pooling Layer가 어떤 역할을 하는지 보겠다.
위의 그림에서 필터는 입력이미지에서 한칸씩 이동하면서 해당 이미지가 있는지 없는지를 검사한다. 예시를 들어 고양이 귀에 대한 필터라고 하자. 만약 필터가 고양이 귀와 제일 비슷한 이미지 부분를 찾으면 값이 가장 크게 나오게 된다.
그리고 필터 결과의 피쳐맵을 보게되면 귀가 어디에 있는지 확인할 수 있다.
이런식으로 다양한 필터를 만들 수 있다. (ex. 귀 필터, 입 필터, 노란색 필터)
피쳐맵이 의미하는 것은 필터에 있는 이미지와 비슷한 것이 입력 이미지에 있는지를 판단하고 그 위치를 확인할 수 있게 해주는 것이다.

이렇게 필터를 적용할 때 두 가지 고려해야할 요소가 있다.
필터는 가운데 중앙을 기준으로 움직이게 된다. 때문에 이미지의 끝 모서리 부분은 제대로 비교하지 못하는 경우가 생긴다. 따라서 이미지의 바깥에 0으로 채운 값들을 붙이는(원본 이미지의 상하좌우에 한줄씩 추가) 것을 Padding이라고 한다.
다음으로 Striding이 있는데 Striding은 필터를 이동시키는 거리를 의미한다. 원래 한칸씩 필터가 움직이며 확인했다면 Striding 조절을 통해 원하는 칸만큼 더 이동하게 할 수 있다.
이런식으로 Padding과 Striding을 통해 피쳐맵을 다양한 방식으로 구할 수 있다.

이렇게 피쳐맵을 구한 다음 하는 것이 Pooling Layer이다. 이 Pooling Layer에서는 Max Pooling, Average Pooling해서 사이즈를 줄이게 된다.
(위의 예시처럼 4×4의 피쳐맵에서 2×2의 피쳐맵 두 개로)
Max Pooling은 필터에서 얻은 값들의 영역을 나눴을 때 각 영역에 가장 큰 값을 대푯값으로 해서 줄이는 방식이다.
그리고 Average Pooling은 각 영역의 값들의 평균을 구해서 줄이는 방식이다.
이 중에선 사실 Max Pooling이 주로 사용된다.
이 방식들을 통해 이미지의 사이즈도 줄일 수 있을 뿐만 아니라 이미지의 왜곡의 영향도 축소할 수 있다.

이렇게 특징들이 추출된 것을 바탕으로 다시 Fully Connected Layer에 사용하게 된다.
앞서 본 것들을 순차대로 정리해서 보겠다.

먼저 이미지가 입력 데이터로 들어왔었다.
그리고 CNN Layer을 통해서 원본 이미지의 특징들을 통해 피쳐맵들이 만들어졌다. (ex. 귀 필터, 입 필터) 이렇게해서 만들어진 수많은 결과물들을 가지고 다시 1차원 배열로 만든다. (그냥 쭉 연결해서 만든다.) 이제 이것들을 사용해서 분류를 하는 것이다.

이렇게 분류를 할 때 마지막 층이 제일 중요하다.
이 마지막층의 Softmax를 알아야한다.
기존의 단순한 분류문제를 풀 때는 마지막 레이어에 하나의 노드만 놓고 결과를 확인했었다. 그런데 하나에 대해서만 그것이 맞는지 아닌지를 비교하는 것이 아니라 많은 Label들에 대해 예측을 해야한다고 하면 Softmax라는 활성화 함수를 써야한다. 그리고 마지막 레이어에 있는 유닛의 개수는 예측해야하는 Label 범주의 개수만큼 있어야한다.
그래서 Softmax를 쓰면 출력되는 값이 a,b,c,d,.. 이렇게 나오는데 각각 A일 확률, B일 확률, C일 확률, D일 확률 이렇게 정의된다.
저 a,b,c,d,...를 다 더하면 1이 나오고 각각은 확률값이다.
결과물을 하나 봤을 때 이중에서 가장 큰 확률값을 갖는게 예측된 결과이다.
지금까지 배운 것을 정리해서 보도록하겠다.

합성곱을 통해 특징을 추출했고 풀링을 통해 사이즈를 줄이고 노이즈도 처리했다. 마지막으로 FC의 활성함수를 통해서 분류했다. (이 과정에서 합성곱과 풀링은 N번 반복할 수 있다.)
반복할 때마다 수많은 필터를 얻게되고 수많은 필터를 얻게되지만 이는 풀링을 통해 크기가 작아지기 때문에 빠르게 학습이 가능하다.

합성곱 기반은 다양한 이미지 처리 기술은 위와 같다.
제일 대표적인 것은 Object detection & segmentation 이다.
이미지 하나만 보고 거기에 있는 물체가 뭔지를 확인하는 기존의 방식이 아니라 이미지에 있는 물체들 각각을 판단할 수 있게 하는 것이 Object detection & segmentation 이다.
Super resolution은 해상도가 낮은 이미지의 해상도를 높이는 것이다.
실습 예제 2 : MNIST 분류 CNN 모델 - 모델 구현)
[실습1]에 이어 CNN 모델을 구현하고 학습해보겠다.
Keras에서 CNN 모델을 만들기 위해 필요한 함수/메서드 :
1. CNN 레이어
tf.keras.layers.Conv2D(filters, kernel_size, activation, padding)입력 이미지의 특징, 즉 처리할 특징 맵(map)을 추출하는 레이어이다.
■ filters : 필터(커널) 개수
■ kernel_size : 필터(커널)의 크기
■ activation : 활성화 함수
■ padding : 이미지가 필터를 거칠 때 그 크기가 줄어드는 것을 방지하기 위해서 가장자리에 0의 값을 가지는 픽셀을 넣을 것인지 말 것인지를 결정하는 변수. ‘SAME’ 또는 ‘VALID’
2. Maxpool 레이어
tf.keras.layers.MaxPool2D(padding)처리할 특징 맵(map)의 크기를 줄여주는 레이어이다.
(padding : ‘SAME’ 또는 ‘VALID’)
3. Faltten 레이어
tf.keras.layers.Flatten()Convolution layer 또는 MaxPooling layer의 결과는 N차원의 텐서 형태이다. 이를 1차원으로 평평하게 만들어준다.
4. Dense 레이어
tf.keras.layers.Dense(node, activation)node : 노드(뉴런) 개수
activation : 활성화 함수
keras를 활용하여 CNN 모델을 설정하라.
(분류 모델에 맞게 마지막 레이어의 노드 수는 10개, activation 함수는 ‘softmax’로 설정한다.)
답 :

실습 예제 3 : MNIST 분류 CNN 모델 – 평가 및 예측)
[실습2]에 이어서 이번 실습에서는 CNN 모델을 평가하고 예측해보겠다.
Keras에서 CNN 모델의 평가 및 예측을 위해 필요한 함수/메서드 :
■ 평가 방법
model.evaluate(X, Y)evaluate() 메서드는 학습된 모델을 바탕으로 입력한 feature 데이터 X와 label Y의 loss 값과 metrics 값을 출력한다.
■ 예측 방법
model.predict_classes(X)X 데이터의 예측 label 값을 출력한다.
1. evaluate 메서드와 평가용 데이터를 사용하여 모델을 평가하라.
(loss와 accuracy를 계산하고 loss, test_acc에 저장하라)
2. predict_classes 메서드를 사용하여 평가용 데이터에 대한 예측 결과를 predictions에 저장하라.
답 :

이번에는 자연어 처리를 위한 데이터 전 처리에 대해 알아보겠다.
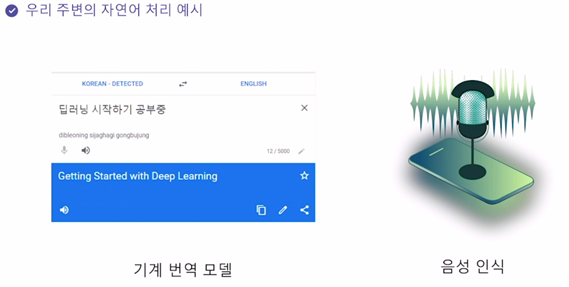
자연어 처리의 예시에는 먼저 구글번역기와 같이 자연어 문장을 넣었을 때 번역된 결과를 주는 기계 번역 모델이 있다. 그리고 아이폰의 시리나 갤럭시의 빅스비처럼 음성 인식을 하는 것도 자연어를 처리하는 예시이다.
이러한 자연어 처리는 다음과 같은 처리 과정을 가진다.

먼저 자연어 전 처리를 수행하고 그것에 대해 단어를 어떻게 표현할지 Word Embedding 과정을 거치게 되고 마지막으로 딥러닝 모델에 적용하게 된다.
첫 과정인 자연어 전 처리부터 알아보겠다.

자연어 전 처리 방법에는 굉장히 여러 가지 방식이 있는데 여기서는 Noise canceling, Tokenizing, StopWord removal 세 가지 방식에 대해 알아보겠다.
먼저 Noise Canceling 방식이다.

위의 예시처럼 문장의 문법적 오류, 잘못된 부분을 표준어에 맞게 바꾸는 것이 Noise Canceling이다. 인간에게는 쉽지만 기계가 처리하는 것은 생각보다 어려울 수 있다.
다음으로 Tokenizing이다.

위와 같이 문장을 어절 또는 단어 등으로 목적에 따라 토큰으로 나누는 것이다.
이미지 데이터와 마찬가지로 자연어 데이터도 바로 딥러닝 모델에 넣을 수 없다.
따라서 수치로 변환해주는 과정이 필요하다. 하지만 큰 문장을 수치로 변환하는 것은 쉽지 않다. 그래서 토큰으로 나누어 변환하는 것이다.
마지막으로 StopWord removal이다.

감탄사와 의성어와 같은 불필요한 단어를 제거한다.
예를 들어 뉴스 기사의 카테고리를 분류할 때, 해당 기사가 정치 기사인지 경제 기사인지 분류하려면 감탄사나 의성어와 같은 단어는 필요가 없을 것이다.(물론 기사에는 그런 단어가 없겠지만 예를 들자면) 이렇게 중요하지 않다고 생각되는 단어를 불용어라고 정의하고 없애주는 것이 바로 StopWord removal이다.
이제 위의 과정들을 통해 만들어진 데이터를 수치형 데이터로 변환해야한다.
수치형 변환을 하기 위해서 알아야 할 개념이 있는데,
바로 Bag of Words이다.

아까 위에서 봤던 세 가지 과정을 거쳐서 위의 예시와 같이 두 가지 토큰화된 자연어 데이터 리스트를 얻었다고 하자.
Bag of Words는 말 그대로 단어들의 가방이다.
왼쪽 자연어 데이터의 모든 사용되는 토큰들을 다 뽑아내서 그것에 대해 인덱스를 부여하는 것이 Bag of Words이다.
(인덱스가 크고 작고는 의미없고 그냥 들어간대로 부여되었다고 생각하면 된다.)
이렇게 Bag of Words를 만들고 나면 본격적으로 자연어 데이터를 수치로 변환할 수 있다.

자연어 데이터로 들어온 리스트에 있는 토큰들을 각각에 해당되는 매핑된 인덱스로(Bag of Words) 변환해주는 것이 수치형 변환이다.
그럼 오른쪽의 토큰 시퀀스와 같이 변환된다.
근데 보면 마지막 리스트를 변환할 때 맨 끝에 4가 붙었다. 이것은 Padding인데 리스트의 요소가 3개가 나오다가 2개가 나왔기 때문에 맞춰줘야하므로 마지막에 쓸모없는 값인 Padding을 붙이는 것이다. (이미지 전 처리에서 통일할 때 해상도를 통일하던 것과 똑같다.)
자연어 데이터의 리스트에서 가장 긴 길이를 기준으로 나머지 리스트들에 Padding을 부여해 맞춰준다고 생각하면 된다.
근데 어떤 한 문장만 너무 긴 경우 그 문장만 제외해두고 먼저 처리하는 것이 좋다.
이렇게 자연어 데이터에 대해 전 처리를 어떻게 하는지 알아봤다.
실습 예제 1 : 영화 리뷰 긍정/부정 분류 RNN 모델 - 데이터 전 처리)
영화 리뷰 데이터를 바탕으로 감정 분석을 하는 모델을 학습 시켜 보아라. 영화 리뷰와 같은 자연어 자료는 곧 단어의 연속적인 배열로써, 시계열 자료라고 볼 수 있다. 즉, 시계열 자료(연속된 단어)를 이용해 리뷰에 내포된 감정(긍정, 부정)을 예측하는 분류기를 만들어 보아라.
데이터셋은 IMDB 영화 리뷰 데이터 셋을 사용한다. 훈련용 5,000개와 테스트용 1,000개로 이루어져 있으며, 레이블은 긍정/부정으로 두 가지이다. 우선 자연어 데이터를 RNN 모델의 입력으로 사용할 수 있도록 데이터 전 처리를 수행해보겠다.
RNN을 위한 자연어 데이터 전 처리 :
RNN의 입력으로 사용하기 위해서는 자연어 데이터는 토큰화 및 여러 가지의 데이터 처리가 필요하다. 아래와 같이 자연어 데이터가 준비되어 있다면 마지막으로 패딩을 수행하여 데이터의 크기를 통일해야한다.
● 첫 번째 데이터 시퀸스:

● 단어 사전:

sequence.pad_sequences(data, maxlen=300, padding='post')
data 시퀀스의 크기가 maxlen인자보다 작으면 그 크기에 맞게 패딩을 추가한다.
인덱스로 변환된 X_train, X_test 시퀀스에 패딩을 수행하고 각각 X_train, X_test에 저장하라. (시퀀스 최대 길이는 300으로 설정한다.)
답 :

실행 결과 :

이제 자연어 처리를 위한 딥러닝 모델에 대해 배워보겠다.

위에서 Bag of Words를 통해서 자연어 데이터 토큰들을 수치형으로 변환할 수 있었다.
근데 이 Bag of Words에는 단점이 있는데 바로 토큰의 의미가 숫자(인덱스)에 반영되어 있지 않다는 것이다.
이때, 이 값들을 의미있는 값들로 바꿔주는 것이 Word Embedding이다.
Word Embedding할 때 Embedding table을 통해서 변환을 할 수 있다. Bag of Words에 있는 인덱스에 따라서 어떤 값으로 변환할지 테이블안에 벡터가 주어진다.
이 벡터는 토큰의 특징을 설명한다. 벡터를 사용하면 벡터간의 유사도도 구할 수 있고 연산도 가능하다. 유사도를 구할 수 있다는 것은 두 토큰간의 의미가 비슷하다는 것을 알 수 있을 것이다. 또 연산이 가능하므로 두 토큰을 더해 새로운 토큰(단어)을 만들어 낼 수 있다.
따라서 이렇게 벡터를 사용하면 의미없는 인덱스에서 특징을 갖는 형태로 변환이 가능하다.
정리하면 단어의 특징을 나타내기 위해 Word Embedding을 하는 것이다.

그래서 Embedding Table을 이용하면 위와 같이 변환할 수 있다.
이렇게 Embedding 된 후에 딥러닝 모델에 사용할 것인데, CNN에서도 이미지 데이터가 2차원 배열이기 때문에 기존 다층 퍼셉트론 신경망을 이용하는 경우 그냥 1차원 배열로 나열해줬었다. 여기서도 마찬가지로 그냥 1차원으로 나열해주면 각각의 특징들이 허물어질뿐만아니라 입력값이 너무 많아져 성능이 떨어진다.
그렇기 때문에 기존 MLP 모델에 적용시키기에는 한계가 있었고 이에 대한 새로운 모델이 필요하게 된다. 이것이 RNN 모델이다.

위의 것이 RNN 모델이다. 순환 신경망이라고 부르는데 이 순환 신경망도 퍼셉트론과 굉장히 비슷한 일을 하긴한다. 거기에 추가적인 기능이 딱 하나 있다.
X 입력 데이터를 받아서 RNN이라는 곳에서 어떤 계산을 통해서 Y를 만들게 된다. X 입력 데이터에는 아까 봤던 Embedding 데이터가 들어가게 된다.
Y값으로는 벡터형태가 나올 수도 있고 0에서 1사이 값이 나올수도 있고 그것은 커스텀하는 것에 따라 달라진다.

그림만 봤을 때는 퍼셉트론과 비슷하다고 생각할 수 있다. 하지만 RNN은 독특한 특징을 가지고 있는데, 바로 출력값이 두 갈래로 나뉘어서 다음 RNN을 계산할 때 전에 사용했던 계산이 들어간다는 특징을 갖는다.
위의 예시를 보겠다.
X 데이터가 RNN에 들어가서 나온 값이 Y뿐만 아니라 h로도 간다. 그리고 옆의 RNN에 들어가게 된다. (옆의 RNN도 마찬가지로 또 다른 입력값을 받는다.) 즉, 옆의 RNN이 또 다른 이 RNN의 X 입력값을 받아 Y값을 만들 때 그 전에 사용했던 X 입력값의 RNN 결과값이 영향을 주는 것이다.
결국 학습할 때 RNN의 특징은 전에 사용했던 토큰에 대한 기억을 받아와서 다음 토큰에 사용하는 것이다. (문장 데이터에 대해 학습할 때 그 전에 사용됐던 토큰들에 대한 기억이 남아있다.)
신경망에서 기억하는 기능이 부여된 것이 RNN이다.
한 가지 예를 보겠다.

(실제로는 [수업이]와 같은 것이 바로 들어가는 것이 아니라 벡터가 들어갈 것이다.)
이렇게 해서 나온 값 Y에 대해서 FC Layer에 넣어서(유닛 하나짜리) 값이 0인지 1인지를 판단하게 한다. 이렇게하면 문장이 긍정인지 부정인지 판단할 수 있다.
이 모델에서는 앞서 나온 세 가지 output인 Y 값에 대해서는 전혀 상관하지 않는다. 맨 마지막에 나온 결과물만 보기 때문에 여기에 대한 계산을 한다고 보면 된다.
이제 지금까지 했던 과정을 다시 정리해보겠다.

먼저 자연어 전 처리를 통해서 정리된 데이터가 임베딩을 통해 특징들을 뽑게 된다. 이 특징들을 바탕으로 RNN이라는 딥러닝 모델을 사용하는데, 이 RNN 모델은 기억하는 딥러닝 모델이다. 그래서 앞서 사용됐던 토큰에 대한 기억들이 같이 다 학습되기 때문에 RNN을 사용하면 문장에 있는 서로간의 순서관계가 포함된다. 그 이후에 활성함수를 통해서 분류를 할 수 있다. multi class 같은 경우에는 softmax 같은 거 사용하면 되고 binal class 같은 경우에는 sigmoid 사용하면 된다. 회귀 같은 경우에는 활성함수 없이 그냥 뽑아내도 된다. 그러고 Loss는 MSE 같은 거 사용해서 처리하면 된다.
그래서 이런 순환 신경망을 사용한 기술에는 다양한 것들이 있다.

대표적으로 Image captioning과 Chat bot이 있다.
Image captioning은 이미지 데이터를 받아 위의 예시와 같이 문장으로 표현해주는 것이다. (CNN 특징 -> RNN) RNN은 위와 같이 label을 시퀀스 형태의 label로 만들 수 있다는 특징도 있다. (나온 output들을 다 이으면 시퀀스 형태가 되므로)
RNN은 가장 기본적인 순환 신경망이고 RNN의 단점들을 보완하는 LSTM이라든지 GRU, TRANSFRO와 같은 것들도 있고 발전중이다.
실습 예제 2 : 영화 리뷰 긍정/부정 분류 RNN 모델 – 모델 학습)
[실습1]에서 전 처리한 데이터를 바탕으로 RNN 모델을 구현하고 학습을 수행해보아라.
Keras에서 RNN 모델을 만들기 위해 필요한 함수/라이브러리 :
일반적으로 RNN 모델은 입력층으로 Embedding 레이어를 먼저 쌓고, RNN 레이어를 몇 개 쌓은 다음, 이후 Dense 레이어를 더 쌓아 완성한다.
■ 임베딩 레이어
# 들어온 문장을 단어 임베딩(embedding)하는 레이어
tf.keras.layers.Embedding(input_dim, output_dim, input_length)○ input_dim: 들어올 단어의 개수
○ output_dim: 결과로 나올 임베딩 벡터의 크기(차원)
○ input_length: 들어오는 단어 벡터의 크기
■ RNN 레이어
# 단순 RNN 레이어
tf.keras.layers.SimpleRNN(units)○ units: 레이어의 노드 수
RNN 모델을 구현하라. (임베딩 레이어 다음으로 SimpleRNN을 사용하여 RNN 레이어를 쌓고 노드의 개수는 5개로 설정하라.)
답 :

실행 결과 :

실습 예제 3 : 영화 리뷰 긍정/부정 분류 RNN 모델 – 평가 및 예측)
[실습2]에 이어서 이번 실습에서는 RNN 모델을 평가하고 예측해보아라.
Keras에서 RNN 모델의 평가 및 예측을 위해 필요한 함수/메서드 :
■ 평가 방법
model.evaluate(X, Y)evaluate() 메서드는 학습된 모델을 바탕으로 입력한 feature 데이터 X와 label Y의 loss 값과 metrics 값을 출력한다.
■ 예측 방법
model.predict(X)X 데이터의 예측 label 값을 출력한다.
1. evaluate 메서드를 사용하여 평가용 데이터를 활용하여 모델을 평가하라.
(loss와 accuracy를 계산하고 loss, test_acc에 저장한다.)
2. predict 메서드를 사용하여 평가용 데이터에 대한 예측 결과를 predictions에 저장하라.
답 :

실행 결과 :

'인공지능 공부' 카테고리의 다른 글
| [2021 NIPA AI 교육 이수증] AI 실무 응용 교육 과정 (0) | 2021.10.01 |
|---|---|
| [2021 NIPA AI 교육 이수증] AI 실무 기본 교육 과정 (0) | 2021.09.30 |
| [2021 NIPA AI 교육 - 응용 / 딥러닝] 02 텐서플로우와 신경망 (0) | 2021.08.25 |
| [2021 NIPA AI 교육 - 응용 / 딥러닝] 01 퍼셉트론 (1) | 2021.08.24 |
| [2021 NIPA AI 교육 - 응용 / 머신러닝] 04 지도 학습 - 분류 (0) | 2021.08.22 |