
오늘은 딥러닝을 어떻게 학습시키는지 방법을 배우고 텐서플로우를 바탕으로 딥러닝을 구현해보겠다.

지난 시간에 히든층이 많아지면 신경망이 더 깊어지고 이를 딥러닝이라고 한다고 했다.
이 딥러닝의 구성요소에 대해 알아보겠다.

보라색 원은 노드 또는 유닛이라고 부른다. 노드는 각 층을 구성하는 요소이다.
그리고 이 노드들을 연결하는 선을 가중치라고 얘기한다. 이 가중치는 노드 사이의 연결강도를 정한다.
마지막으로 모델을 구성하는 층을 레이어라고 한다.
이제 본격적으로 딥러닝 모델의 학습 방법에 대해 알아보겠다.

퍼셉트론, 딥러닝 둘 다 마찬가지로 최종적인 목적은 Loss 함수를 최소화하는 가중치를 찾는 것이다. 이것이 딥러닝 모델의 학습 방법이다.
이 가중치를 찾기 위해서는 최적화 알고리즘을 사용하게 되는데 뒤에서 추가적으로 보겠다.
먼저 예측값부터 딥러닝을 통해 어떻게 구할 수 있는지 알아보겠다.

첫 번째 입력단에서 시작하여 점진적으로 값을 구하는 방식을 순전파(Forward propagation)이라고 한다.
계산과정이 많을 수는 있다.
첫 번째 퍼셉트론부터 하나씩 값을 구해가며 값을 뒤쪽까지 전달해주는 방식이다.
이 방식을 통해 최종적인 예측값을 구할 수 있다.
아래 순전파 예시를 보며 다시 설명하겠다.

이런식으로 첫 번째 층의 퍼셉트론들의 값이 다음 층의 퍼셉트론에 입력값으로 쓰여 전파된다.
여기까지 순전파를 통해 예측값을 구해보았다.
이제 순전파를 통해 구한 예측값을 가지고 어떻게 최적화를 하는지 알아보겠다.

오차가 줄면 줄어들수록 Loss도 준다.
이 경우 어떻게 최적화 해야할지에 대한 고민이 있을 수 있다.
딥러닝에서는 최적화 방식으로 경사 하강법을 사용한다.

경사 하강법은 머신러닝 선형 회귀에서도 쓰였었다.
경사 하강법은 가중치를 Loss 함수 값이 작아지게 업데이트 하는 방법이다.
한 번에 Loss 값이 제일 작게 만드는 것이 아니라 점진적으로 업데이트하는 방식을 의미한다.
그리고 이 가중치는 Gradient 값을 사용해 업데이트 한다는 것이 핵심이다.
가중치에 대해서 각각의 Gradient 값을 구해줘야하고 이 Gradient 값은 역전파라는 방식을 통해 구할 수 있다.
정리 : 우리가 구하는 것은 가중치. 가중치를 구하기 위해선 Gradient 값이 필요. Gradient는 역전파를 통해 구할 수 있다.

예시를 들자면 w6에 대한 Gradient를 구했다면 이를 바탕으로 그 전 노드에 있는 w3와 w4에 대해서 Gradient를 구할 수 있다.
다시 말하자면 w3에 대한 Gradient를 구하고 싶다면 다음 노드인 w6에 대한 정보가 필요하다.
그래서 우선적으로 다음 노드에 있는 값을 구한 다음에 그 전 노드로 전달을 해줘야 전 노드에 있는 w3의 Gradient값을 구할 수 있다.
그러므로 순서를 보자면 제일 끝 Layer에 있는 노드의 Gradient를 제일 먼저 구하고, 그 바로 전 노드의 Gradient를 구하고, ... 이렇게 된다.
그렇다면 지금까지의 과정을 조금 정리해보겠다.

입력단에 값이 도착하게 되면 이것을 바탕으로 순전파를 통해 값을 전달하며 최종적인 예측값을 구할 수 있다.
그리고 이 예측값과 실제값 사이의 오차를 통해 Loss를 구할 수 있다. 이 Loss를 바탕으로 해서 Gradient값을 구한다.
이 값을 역전파하며 가중치들의 Gradient 값들을 구할 수 있다.
그리고 이것들을 이용해 가중치들을 업데이트 한다.
순서 :
1. 순전파로 예측값 구하기
2. 역전파로 Gradient 값 구하기
3. 가중치 업데이트하기
이 과정을 계속 반복하면 Loss 함수를 가장 작게 만드는 가중치를 구할 수 있다.

위 과정을 반복하는 것이 딥러닝 모델의 학습 방법이다.
이제 텐서플로우로 딥러닝을 구현해보겠다.
먼저 텐서플로우가 무엇인지부터 알아보고 가겠다.

텐서플로우는 파이썬 딥러닝 프레임워크이다.
다양한 디바이스에서 동작이 가능하다는 장점이있다.
가장 많이 쓰이는 딥러닝 프레임워크에 텐서플로우와 파이토치가 있는데 그 중 텐서플로우를 쓰겠다.
텐서플로우로 딥러닝 모델을 구현할 때 네 가지 과정이 있다.

먼저 데이터 전 처리가 왜 필요한지 알아보겠다.

텐서플로우 딥러닝 모델은 다차원 배열 형태의 텐서플로우에서 사용하는 객체인 Tensor 형태의 데이터를 입력받는다.
기존 데이터를 Pandas나 NumPy로 정리를 할 수 있는데 이 정리된 데이터를 다시 한번 Tensor로 변환해줘야 한다.

Tensor형태의 데이터로 만들기 위해서는 tf.data.Dataset 라는 객체로 만들어야 한다.
위의 예시를 통해 Pandas로 데이터를 불러왔을 때 이것을 어떻게 변환하는지 보도록 하겠다.
우선 read_csv로 데이터를 불러오고, drop으로 label 컬럼을 떼고 feature 변수에 넣고 label 컬럼은 label 변수에 넣는다.
그리고 tf.data.Dataset안의 메서드 from_tensor_slices 메서드를 사용해서 tensor로 변환할 수 있다. 여기에 들어가는 데이터로는 feature 데이터와 label 데이터가 들어가게 된다.
하지만 Pandas의 DataFrame 형태로 들어가는 것이 아니라 .values를 통해서 다시 배열로 변환해주고 전달해준다.
이렇게 Tensor로 잘 정리했다.
이제 데이터에 추가적인 전 처리를 해야한다.
딥러닝에 사용되는 전 처리는 Epoch와 Batch가 있다.
(사실 Batch라고 생각하면 되지만 이 Batch를 알기 위해서는 Epoch에 대한 개념도 필요하기 때문에 두 가지 모두에 대해서 설명하겠다.)

먼저 Epoch는 Data set에 대해 한 번 학습을 완료한 상태를 의미한다.
위의 그림처럼 Data set이 주어졌을 때 이 Data set을 전체 한번 쭉 학습하는 과정을 하나의 Epoch다 라고 생각하면 된다.
그랬을 때 Batch라는 것은 Data set을 나눈 것을 의미한다. 그래서 Batch의 size만큼 Data set을 나누게 되고 그것을 보통 mini-batch라고도 얘기한다.
하나의 Epoch안에 여러개의 Batch들이 존재하게 된다.
그리고 이 Batch를 한 번 수행하는 것을 iteration이라고 한다.
이러한 개념이 왜 있는 것일까?
딥러닝의 학습 과정에서는 한 두 개가 아니라 엄청 많은 수의 가중치들을 업데이트 해야한다. 이 계산을 한 번에 전체 Epoch만큼 넣고 하면 힘들기 때문에 이것을 쪼개서 넣어보는 것이다. 그것이 Batch이다.
정리하면 가중치를 업데이트 할 때 전체 한 개의 Epoch를 넣는 것이 아니고 Batch를 나누어 각각 하나씩 넣으며 업데이트 하는 것이다.
그리고 Batch하나의 계산 과정이 iteration이다.
예시를 보겠다.

그럼 이런 Batch를 어떻게 수행하는지 코드로 보겠다.

Tensor 형태로 데이터를 변환하는 위의 코드는 아까 봤었다.
이렇게 Tensor 형태로 변환된 데이터에 batch라는 메서드를 사용하고 인자로 batch size를 적어주면 이것에 맞는 batch들이 생성되게 된다.
실습 예제 – 데이터 전 처리)
텐서플로우를 활용하여 신경망을 구현하라.
광고 비용에 따른 수익률을 신경망을 통해서 예측하고자 한다.
아래와 같이 FB, TV, Newspaper 광고에 대한 비용 대비 Sales 데이터가 주어진다면 우선 데이터 전 처리를 수행하여 텐서플로우 딥러닝 모델에 필요한 학습용 데이터를 만들어 보자.

텐서플로우 신경망 모델의 학습 데이터를 만드는 함수/메서드 :
텐서플로우 신경망 모델의 학습 데이터는 기존 데이터를 tf.data.Dataset 형식으로 변환하여 사용한다.
pandas의 DataFrame 형태 데이터를 Dataset으로 변환하기 위해서는 아래의 from_tensor_slices() 메서드를 사용하여 저장할 수 있다.
ds = tf.data.Dataset.from_tensor_slices((X.values, Y.values))(X는 feature 데이터가 저장된 DataFrame이고, Y는 label 데이터가 저장된 Series 이다. 여기서 X, Y 데이터는 X.values, Y.values를 사용하여 리스트(배열) 형태로 입력한다.)
이후 변환된 Dataset에 batch를 적용하고 싶다면 아래와 같이 batach() 메서드를 사용한다.
ds = ds.shuffle(len(X)).batch(batch_size=5)(shuffle 메서드를 사용하여 데이터를 셔플할 수 있다. 인자로는 데이터의 크기를 입력한다.
batch 메서드를 사용하여 batch_size에 batch size를 넣게 되면 해당 크기로 batch를 수행하게 됩니다.)
이렇게 처리한 ds에서 take()메서드를 사용하면 batch로 분리된 데이터를 확인할 수 있다.
1. pandas DataFrame df에서 Sales 변수는 label 데이터로 Y에 저장하고 나머진 X에 저장하라.
2. 학습용 데이터 train_X, train_Y를 tf.data.Dataset 형태로 변환하라 (from_tensor_slices 함수를 사용하여 변환할 수 있다.)
답 :

실행 결과 :

이제 텐서플로우로 모델을 구현해보도록 하겠다.

텐서플로우 모델을 구축할 것인데 텐서플로우의 패키지로 제공되는 고수준 API인 Keras(케라스)라는 것을 사용할 것이다.
사실 Keras를 사용하지 않고도 텐서플로우에 있는 함수들을 통해서 모델을 구현할 수도 있지만 처음하는 사람들에게는 어렵다.
그래서 Keras를 이용해서 쉽게 모델을 구축하고 추후에 텐서플로우만을 통해 구현하는 것도 알아보겠다.

먼저 Keras의 메소드를 알아볼 것이다.
제일 첫 번째로 Sequential()이다.
이 메서드를 사용해 모델의 클래스 객체를 생성할 수 있다.
그리고 Layer를 구성해야하는데 Dense() 안에는 최소한 두 가지에 대해 설정을 해줘야한다. 바로 units과 activation이다.
units은 레이어 안의 노드의 수이고 activation은 적용할 활성화 함수를 고르는 것이다.

이렇게 레이어를 쌓을 때 첫 번째 레이어에서 중요한 부분이 있는데, Input Layer에서는 입력 형태에 대한 정보를 필요로한다.
입력 형태에 대한 정보는 input_shape 또는 input_dim 인자를 통해 설정하여 input layer의 형태를 구성할 수 있다. (둘 중 하나만 사용하면 된다.)
이제 코드를 보면서 실제로 어떻게 코딩하는지 살펴보겠다.

여기서 tf.keras.layers.Dense(10, input_dim=2, activation=‘sigmoid’)라는 코드로 아래와 같은 층 구조를 만들 수 있다.

그리고 두 번째 줄코드로 두 번째 층을 만들어준다. 여기는 두 번째 layer기 때문에 입력에 대한 관련된 정보는 넣어주지 않아도 된다.

그럼 위와 같이 추가로 연결된다.
마지막 layer는 노드가 하나다.

마지막 노드가 하나이기 때문에 값은 하나로 나온다.
이렇게 전체적인 모델이 완성됐다.
중요한 포인트는 입력이 두 개고 출력이 하나라는 것이고 히든층은 두 개다.

딥러닝 모델을 만들기 위한 Keras 메소드로 같은 모델을 만들 수 있는데 조금 다른 방법으로 구성할 수 있는 방법에 대해 알아보겠다.
아까는 Sequential([])으로 크게 괄호열고 그 안에 코드를 적었다.
근데 그렇게 하지 않고 model = Sequential() 한다음 model에 .add 해서 코딩해도 된다는 것이다.
아래는 예시코드이다.

이번에는 딥러닝 모델을 학습시키는 방법에 대해서 배워보겠다.
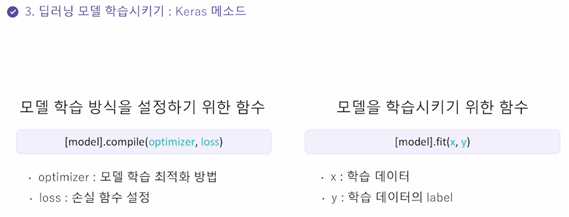
모델 학습을 위해서는 여러 가지 설정이 필요한데 compile이 그 설정 함수이다.
여기서는 가장 중요한 optimizer와 loss를 설정해야 한다.
optimizer은 모델 학습 최적화 방법으로 아까 배운 경사하강법(GD)등이 있고 loss는 손실함수로 회귀에서 배운 MSE등이 있다. (분류에서는 Cross Entropy) 이것들을 각각 설정하는 것이다.
이렇게 모델을 설정하고 나서는 실질적으로 모델을 학습하기 위한 함수를 사용한다.
이것은 머신러닝에서도 많이 사용했던 fit() 함수를 사용한다.
인자로 들어가는 x 데이터는 feature 데이터이고 y 데이터는 label 데이터이다.
근데 꼭 이렇게 x, y로 나누어 넣지 않고 앞에서 봤던 Tensor 형태의 Data set을 그냥 넣어줘도 된다.
이제 아래에서 예시를 보겠다.

compile에서 학습 방식을 설정하고 fit함수로 학습을 한다.
fit()함수에서 epochs=100은 100개 만큼 학습을 수행한다고 생각하면 된다.
만약 batch가 설정되어 있다면 한 번의 epoch에서 batch 만큼 계속 돌아가게 된다고 생각하면 된다.
이제 앞서 한 학습을 수행한 것을 평가하는 방법에 대해 알아보겠다.

평가용으로 사용할 테스트 데이터의 feature 부분과 label 부분을 evaluate 함수에 넣으면 평가가 가능하다.
그리고 predict 함수를 통해서는 들어온 x 데이터에 대해 예측값을 반환한다.
아래는 예시 코드이다.

실습 예제 1 – 모델 구현)
텐서플로우와 케라스(Keras)를 활용하여 신경망 모델을 구현하라.
케라스는 텐서플로우 내의 신경망 모델 설계와 훈련을 위한 API 이다. 케라스는 연속적으로(Sequential) 레이어(Layer)들을 쌓아가며 모델을 생성하고, 사이킷런과 같이 한 줄의 코드로 간단하게 학습 방법 설정, 학습, 평가를 진행할 수 있다.
텐서플로우와 케라스를 이용해 신경망 모델을 만들기 위한 함수/메서드 :
■ 모델 설정
# 연속적으로 층을 쌓아 만드는 Sequential 모델을 위한 함수
tf.keras.models.Sequential()
■ Dense 레이어
# 신경망 모델의 레이어를 구성하는데 필요한 keras 함수
tf.keras.layers.Dense(units)(units는 레이어 안의 노드 수이다.)
예를 들어, 5개의 변수에 따른 label 을 예측하는 회귀 분석 신경망을 구현하고 싶다면 아래와 같이 구현할 수 있다.
tf.keras.models.Sequential([
tf.keras.layers.Dense(10, input_shape=(5,)),
tf.keras.layers.Dense(1)
])input_shape 인자에는 (입력하는 변수의 개수, )로 입력한다. 또한 회귀 분석이기에 마지막 레이어의 유닛 수는 1개로 설정한다.
input_dim인자를 사용하면 아래와 같이 표현할 수 있다.
tf.keras.models.Sequential([
tf.keras.layers.Dense(10, input_dim=5),
tf.keras.layers.Dense(1)
])
tf.keras.models.Sequential()을 활용하여 신경망 모델을 생성하라. (자유롭게 layers를 쌓고 마지막 layers는 노드 수를 1개로 설정하라.)
코드 :

실행 결과 :

실습 예제 2 – 모델 학습)
[실습1]에 이어서 텐서플로우와 케라스(Keras)를 활용하여 신경망 모델을 학습해보겠다.
텐서플로우와 케라스를 이용해 신경망 모델을 학습하기 위한 함수/메서드 :
■ 학습 방법 설정
model.complie(loss='mean_squared_error', optimizer='adam')complie() 메서드는 모델을 어떻게 학습할 지에 대해서 설정한다. loss는 회귀에서는 일반적으로 MSE인 ‘mean_squared_error’, 분류에서는 ‘sparse_categorical_crossentropy’ 를 주로 사용한다.
■ 학습 수행
model.fit(X, epochs=100, verbose=2)X 데이터를 에포크를 100번으로 하여 학습한다. verbose 인자는 학습 시, 화면에 출력되는 형태를 설정한다. (0: 표기 없음, 1: 진행 바, 2: 에포크당 한 줄 출력)
Dataset으로 변환된 학습용 데이터를 바탕으로 모델의 학습을 수행하라.
1. compile 메서드를 사용하여 최적화 모델을 설정한다. loss는 ‘mean_squared_error’, optimizer는 ‘adam’으로 설정하라.
2. fit 메서드를 사용하여 학습용 데이터를 학습한다. epochs는 100으로 설정하라.
답 :

실행 결과 :

실습 예제 3 – 모델 평가 및 예측)
[실습2]에 이어서 이번 실습에서는 학습된 신경망을 모델을 평가하고 예측해보겠다.
텐서플로우를 이용해 신경망 모델을 평가 및 예측을 위한 함수/메서드 :
■ 평가 방법
model.evaluate(X, Y)evaluate() 메서드는 학습된 모델을 바탕으로 입력한 feature 데이터 X와 label Y의 loss 값과 metrics 값을 출력한다. 이번 실습에서는 metrics 를 complie에서 설정하지 않았지만, 분류에서는 일반적으로 accuracy를 사용하여 evaluate 사용 시, 2개의 아웃풋을 리턴한다.
■ 예측 방법
model.predict(X)X 데이터의 예측 label 값을 출력한다.
1. evaluate 메서드를 사용하여 테스트용 데이터의 loss 값을 계산하고 loss에 저장하라.
2. predict 메서드를 사용하여 테스트용 데이터의 예측값을 계산하고 predictions에 저장하라.
답 :

실습 예제 4 – 신경망 모델로 분류하기)
Iris 데이터가 주어졌을 때 붓꽃의 종류를 분류하는 신경망 모델을 구현하라.
Iris 데이터는 아래와 같이 꽃받침 길이, 꽃받침 넓이, 꽃잎 길이, 꽃잎 넓이 네 가지 변수와 세 종류의 붓꽃 클래스로 구성되어 있다.

분류를 위한 텐서플로우 신경망 모델 함수/메서드 :
■ 모델 구현 (5개의 범주를 갖는 label 예시)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, input_dim=4),
tf.keras.layers.Dense(5, activation='softmax')
])분류 모델에서는 마지막 레이어에 분류 데이터의 label 범주의 개수만큼 노드를 설정한다. 추가로 activation 인자로 ‘softmax’ 를 설정한다.
■ 학습 방법
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])분류에서는 일반적으로 loss를 ‘sparse_categorical_crossentropy’으로 사용한다. metrics 인자는 에포크마다 계산되는 평가 지표를 의미한다. 정확도를 의미하는 ‘accuracy’ 를 입력하면 에포크마다 accuracy를 계산하여 출력한다.
keras를 활용하여 신경망 모델을 생성한다. 3가지 범주를 갖는 label 데이터를 분류하기 위해서 마지막 레이어 노드를 아래와 같이 설정한다.
- 노드의 수는 3개
- activation은 ‘softmax’로 설정한다.
답 :

'인공지능 공부' 카테고리의 다른 글
| [2021 NIPA AI 교육 이수증] AI 실무 기본 교육 과정 (0) | 2021.09.30 |
|---|---|
| [2021 NIPA AI 교육 - 응용 / 딥러닝] 03 다양한 신경망(이미지, 자연어 처리 CNN, RNN) (0) | 2021.08.30 |
| [2021 NIPA AI 교육 - 응용 / 딥러닝] 01 퍼셉트론 (1) | 2021.08.24 |
| [2021 NIPA AI 교육 - 응용 / 머신러닝] 04 지도 학습 - 분류 (0) | 2021.08.22 |
| [2021 NIPA AI 교육 - 응용 / 머신러닝] 03 지도 학습 - 회귀 (0) | 2021.08.21 |