이번 시간에는 분류의 개념에 대해 알아보고 분류 모델을 사용할 의사 결정 나무에 대해서 배우고 이를 평가하는 지표에 대해 알아보겠다.
먼저 문제를 가정해보겠다.

해외 여행을 준비하고 있었다.
완벽한 여행을 위해 항공 지연을 피하고자 한다.
기상 정보 (구름 양, 풍속)를 활용하여 해당 항공의 지연 여부를 예측할 수 있을까?
이럴 때 문제 정의를 해보면 아래와 같다.

예측해야 하는 label 데이터인 Y, 입력 데이터인 feature 데이터 X가 주어졌으므로 이는 지도 학습이다.
예측 해야하는 자료의 형태를 보면 Yes 또는 No로 범주형이다.
이렇게 범주형인 경우에는 분류 알고리즘으로 풀어야한다.
그렇다면 분류란 무엇일까?

예측해야 할 label에 있는 범주를 분류에서는 클래스라고 많이 한다.
이제 분류 문제를 한 번 풀어보겠다.

앞에 있던 데이터를 풍속 4m/s를 기준으로 지연 여부를 나눠보겠다.
이 경우 예를 들어 6m/s 가 입력값으로 들어오면 지연이 있다고 머신 러닝이 예측할 수 있다.
이렇게 4m/s로 바꾸는 것은 굉장히 단순한 모델이다.
하지만 이것도 엄연히 머신러닝 모델이고 이 모델은 데이터를 통해 학습해서 분류 기준을 만들었다고 볼 수 있다.
이러한 분류 알고리즘에는 어떤 것들이 있을지 알아보겠다.

분류 문제에는 다양한 머신러닝 모델들이 사용되는데 간단히 정리했을 때 트리 구조 기반, 확률 모델 기반, 결정 경계 기반, 신경망과 같은 모델을 사용한다.
우리는 처음 머신러닝을 시작하는 것이므로 이 중 가장 간단한 모델 중 하나인 의사결정나무 모델에 대해 알아보겠다.
이 의사결정나무 모델은 간단한 모델임에도 생각보다 성능도 매우 좋고 이것으로 확장할 수 있는 모델도 매우 많다.
이 의사결정나무의 모델 구조에 대해 알아보겠다.
우선 의사결정나무(Decision Tree)가 무엇인지 먼저 알아야한다.

우측에 있는 그림과 같은 형태로 위에서 아래로 진행한다.
이 의사결정나무를 통해 어떻게 분류가 되는지 앞서 봤던 가정을 가지고 예시를 보겠다.

이렇게 예측을 할 수 있게끔 질문을 만들고 구조를 만드는 것이 의사결정나무라고 볼 수 있다.

아까 전까지는 간단하게 두 가지로 나눴다. 근데 이번에 주어진 데이터를 보면 아까와 같이 4m/s를 기준으로 두 가지로만 나누기는 어려울 것 같다.
따라서 이번에는 두 가지 이상의 분류 기준으로 나눌 것이다.

아까는 뿌리 마디밖에 없었는데 이번엔 중간 마디를 추가할 것이다.

이번에는 feature 데이터의 개수가 2개 이상일 때이다.
이 경우에도 중간 마디를 이용해 잘 나눠주면 된다. (각각의 변수에 대해 질문해주면 되는 것이다.)

그럼 지금까지 살펴봤던 의사결정나무에 대해 훑어보면서 구조도 살펴보겠다.
뿌리 마디로부터 시작해 중간 마디를 거치고 끝 마디에 도달하는 과정에서 각각의 마디에 분류 기준이 있었다.
그리고 최종적으로는 끝마디에 도달하는데 그렇게 분류된 것들을 클래스라고 했다.
실습 예제 1)
위에서 나왔던 항공 지연 데이터를 기반으로 간단한 의사결정나무를 구현해 보아라.

풍속에 따른 지연 여부를 알아내기 위하여 의사결정나무인 binary_tree의 기준값(threshold)을 변경해가며 완벽하게 지연 여부를 분리할 수 있는 모델을 만들어 보아라
정의된 binary_tree 함수는 입력하는 threshold 풍속을 기준으로 지연 여부를 예측한 결과를 DataFrame 형태로 출력하게 짜여져있다. data의 지연 여부와 예상 지연 여부가 같은 값이 나오도록 의사결정나무의 결과물을 data_pred에 저장하라.
threshold 에 값을 넣어서 결과를 확인할 수 있다. (ex) 1, 2, 3.5, …)
답 :

return data_no.append(data_yes, ignore_index=True)
에서 보면 data_no에 append로 data_yes를 합치게 된다.
ignore_index는 합치면서 새롭게 인덱스를 만들어 달라는 것이다.(안하면 인덱스가 따로따로 유지돼 012012 이런식으로 된다.)
실행 결과 :

지금까지 의사결정나무의 구조를 살펴봤다.
그 구조에서 제일 중요한 것 중 하나가 분류 기준이었다.
이 분류 기준은 어떻게 정하는지 지금부터 하나씩 알아보겠다.

데이터가 위와 같이 주어졌다고 하자.
아까 처음에 봤던 데이터는 분류 기준이 명확했지만 이번의 데이터는 분류기준을 딱 잡기가 쉽지 않다.

이 경우 데이터의 불순도를 최소화하는 구역으로 나누는 방법이 있다.
불순도(Impurity)란 다른 데이터가 섞여 있는 정도를 의미한다.

눈으로 보면 A가 B보다 불순도가 낮다는 것을 알 수 있다.
하지만 데이터가 많이 존재하게 되면 눈으로 보는 것은 정확하지 않다.
그렇기 때문에 정확한 수치로 계산을 해야하고 이를 어떻게 계산하는지를 알아보겠다.

마치 회귀에서 Loss함수를 MSE로 뒀던 것처럼 의사결정나무에서는 불순도를 측정할 때 다양한 방식 중 지니 불순도를 이용한다. (이것 외에 유명한 방식으로 엔트로피 방식도 있다.)
먼저 지니 불순도를 구하기 위해서는 지니 계수를 구해야 하는데, 지니 계수는 해당 구역 안에서 특정 클래스에 속하는 데이터의 비율을 모두 제외한 값이다.
지니 인덱스에 대해서 자세히 알 필요는 없고 이렇게 구해진다는 것만 알고 넘어가자.

어떤 기준으로 데이터를 두 가지로 분류 했을 때 각각에 대해 Gini Index를 구할 수 있다.
이 두 개의 Gini Index를 가지고 구할 수 있는 것이 우리가 구하고 싶은 Gini Impurity(지니 불순도)이다.
이 Impurity가 작으면 작을수록 좋은 것이다.

그러면 이제 이 지니 불순도를 실질적으로 계산해보겠다.
빨간선(약 2.5)을 기준으로 나누면 위쪽의 Gini index는 0이고 아래쪽의 Gini index는 1/2이다.
그리고 각각의 Gini index 앞에 n/N을 곱해준다.
n은 해당 클래스의 개수이고 N은 전체 데이터의 개수이다.

이런 기준들을 여러개 설정해서 각각의 지니 불순도를 구한다.
이렇게 구해진 지니 불순도 중 가장 낮은 값을 갖는 기준을 나누는 기준으로 잡으면 된다.
이제 이렇게 구한 지니 불순도를 적용하는 방법에 대해 알아보겠다.

먼저 뿌리 노드에서 지니 불순도를 계산한다. 그리고 가장 낮은 불순도를 갖는 기준을 가지고 데이터를 분리한다. 이렇게 나누어 새로운 중간 노드를 만들고 이 중간 노드에서 다시 지니 불순도를 계산해 또 다시 나눈다. 이런 식으로 끝 노드가 나올 때까지 반복한다.
지금까지 불순도에 대해 알아보았다.
이제 마지막 파트로 의사결정나무의 장단점에 대해 설명하겠다.
그 중 제일 중요한 파트인 깊이 부분에 대해서 보겠다.

의사결정나무의 깊이란 중간 노드의 개수라고 생각하면 된다.
중간 노드가 많으면 많아질수록 깊이가 깊어진다.
이렇게 깊이가 깊어지면 더욱 세분화해서 나눌 수 있다는 장점이 있다.
하지만 너무 깊이가 깊어지면 과적합을 일으킬 수 있다는 단점이 있다.
과적합이란 너무 세밀하게 예측하는 것을 의미한다. 이렇게 예측하면 오히려 잘못된 예측을 할 가능성이 생긴다. (너무 깊은 모델은 지양)
마지막으로 의사결정나무의 특징에 대해 살펴보겠다.

결과가 직관적이고 트리를 한 번 만들어두면 작업 속도가 빠르다는 장점이 있다.
하지만 너무 세밀하게 분류해 깊이가 깊어지면 Overfitting이 발생해 예측에 문제가 생길 수 있으니 조심하는 것이 좋다.
실습 예제 1 – 데이터 전 처리)
sklearn을 사용한 의사결정나무
분류 문제 해결을 위해 Iris 데이터를 사용한다. Iris 데이터는 아래와 같이 꽃받침 길이, 꽃받침 넓이, 꽃잎 길이, 꽃잎 넓이 네 가지 변수와 세 종류의 붓꽃 클래스로 구성되어 있다.

꽃받침 길이, 꽃받침 넓이, 꽃잎 길이, 꽃잎 넓이 네 가지 변수가 주어졌을 때, 어떠한 붓꽃 종류인지 예측하는 분류 모델을 구현하라.
우선 데이터를 전 처리 하기 위해서 4개의 변수를 갖는 feature 데이터와 클래스 변수를 label 데이터로 분리하고 학습용, 평가용 데이터로 나눠야 한다.
답 :

실습 예제 2 – 학습하기)
[실습1]에서 전 처리한 데이터를 바탕으로 의사결정나무 모델을 학습하라.
각 노드에서 불순도를 최소로 하는 의사결정나무 모델을 구현하기 위해서는 sklearn의 DecisionTreeClassifier을 사용한다. 이 모델을 학습하고 모델의 구조를 살펴보자.
참고 :
DecisionTreeClassifier을 사용하기 위해서는 우선 해당 모델 객체를 불러와 초기화해야 한다. 아래 코드는 DTmodel에 모델 객체를 초기화 하는 것을 보여준다.
DTmodel = DecisionTreeClassifier()
# 아래 코드처럼 초기화를 수행할 때 max_depth로 최대 깊이를 조절할 수도 있다.
# DTmodel = DecisionTreeClassifier(max_depth=2)
모델 초기화를 수행했다면 전 처리된 데이터를 사용하여 학습을 수행할 수 있다. 아래 코드와 같이 fit 함수에 학습에 필요한 데이터를 입력하여 학습을 수행한다.
DTmodel.fit(train_X, train_Y)
1. sklearn의 DecisionTreeClassifier() 모델을 DTmodel에 초기화하라.
2. fit을 사용하여 train_X, train_Y 데이터를 학습하라.
답 :

실행 결과 :

실습 예제 3 – 예측하기)
[실습2]에서 학습한 모델을 바탕으로 새로운 데이터에 대해서 예측하라.
test_X 데이터에 따른 예측값을 구하라.
DecisionTreeClassifier을 사용하여 예측을 해야 한다면 아래와 같이 predict 함수를 사용하라.
pred_X = DTmodel.predict(test_X)
DTmodel을 학습하고 test_X의 예측값을 구하여 pred_X에 저장하라.
답 :

실행 결과 :

이제 분류 평가 지표에 대해 배워보겠다.
분류 알고리즘을 평가하기 위해서는 기본적으로 혼동 행렬(Cofusion Matrix)에 대해 알아야한다.

분류 모델의 성능을 평가하기 위해 가장 기본적인, 밑바탕이 되는 지표들을 계산하는 행렬이다.
위 그림처럼 표현이 된다.
보면 열 부분에는 예측한 결과가 Positive인지 Negative인지로 나뉘게 되고 행 부분에는 실제 데이터가 가지고 있는 label에 대해 Positive인지 Negative인지 판단하는 것을 표로 나타낸 형태로 볼 수 있다.
위에선 Positive, Negative로 표현 되어 있지만 0, 1로도 표현이 가능하다.

True Positive(TP)는 실제 데이터가 Positive인데 예측한 것도 Positive로 잘 예측한 부분을 의미한다.
반대로 True Negative(TN)는 실제 데이터가 Negative인데 예측한 것도 Negative로 잘 예측한 부분을 의미한다.
그리고 False Positive(FP), False Negative(FN)은 잘못 예측한 부분을 의미한다.
이렇게 혼동 행렬을 구하면 어떤 걸 잘 맞췄고 어떤 걸 틀렸는지에 대해서 알 수 있다.
다음으로 정확도(Accuracy)에 대해서 알아보겠다.

정확도란 (제대로 분류된 데이터 = TP + TN) / (전체 데이터 = P + N)를 의미하며 모델이 얼마나 정확하게 분류하는지를 나타낸다.
이것은 일반적인 분류 모델의 주요 평가 방법이다.
그러나 클래스 비율이 불균형하면 신뢰성이 떨어진다는 단점이 있다.
다음으로 정밀도(Precision)에 대해 알아보겠다.

정밀도는 (실제로 Positive인 데이터 = TP) / (모델이 Positive라고 분류한 데이터 = TP + FP) 이다.
이는 FP를 파악하는게 중요한 경우에 쓰인다.
이것에 대해 예를 하나 들어서 보겠다.

이렇게 스팸 메일의 경우 FP를 파악하는게 중요하다. 이때 정밀도를 봐야한다.
다음으로 재현율(Recall, TPR)에 대해 알아보겠다.

재현율은 (모델이 Positive라고 분류한 데이터 = TP) / (실제로 Positive인 데이터 = P) 이다.
(P = TP + FN 이었다.)
이는 FN를 파악하는게 중요한 경우에 쓰인다.
이것도 예를 하나 들어서 보겠다.

악성 종양이 맞는데 아니라고 잘못 예측하면 생명을 위급하게 할 수 있다.
따라서 이 경우 FN이 중요하고 재현율이 중요하다.
이제 지금까지 배웠던 다양한 지표에 대해 언제 사용해야 하는지 정리해보도록 하겠다.

분류 목적에 따라서 다양한 지표를 계산해 평가하는데, 먼저 분류 결과를 전체적으로 보고 싶다면 혼동 행렬을 구해야한다. 그리고 정답을 얼마나 잘 맞췄는지 궁금하다면 정확도를 구해야한다.
FP 또는 FN 의 중요도 따라서는 정밀도 혹은 재현율을 구하면 된다.
그래서 각각 문제가 추구하는 목적에 따라 지표를 정하면 되고 이 지표에 따라 모델을 평가하면 된다.
실습 예제 1 – 혼동 행렬(Confusion matrix) )
혼동 행렬(Confusion matrix)은 분류 문제에서 모델을 학습시킨 뒤, 모델에서 데이터의 X값을 집어넣어 얻은 예상되는 y값과, 실제 데이터의 y값을 비교하여 정확히 분류 되었는지 확인하는 메트릭(metric)이라고 할 수 있다.

■ True Positive (TP) : 실제 값은 Positive, 예측된 값도 Positive.
■ False Positive (FP) : 실제 값은 Negative, 예측된 값은 Positive.
■ False Negative (FN) : 실제 값은 Positive, 예측된 값은 Negative.
■ True Negative (TN) : 실제 값은 Negative, 예측된 값도 Negative.
sklearn 안에는 위 4개 평가 값을 얻기 위해 사용할 수 있는 기능이 정의되어 있다.
2개의 클래스를 가진 분류 데이터를 이용하여 혼동 행렬을 직접 출력해보아라.
혼동 행렬을 위한 사이킷런 함수/라이브러리 :
# 혼동 행렬(Confusion matrix)의 값을 np.ndarray로 반환해준다.
confusion_matrix(y_true, y_pred)(첫 번째 인자에는 실제값 넣고 두 번째 인자에는 예측값 넣는다.)
데이터 정보 :
load_breast_cancer() : 사이킷런에 내장된 유방암 유무 판별 데이터를 불러오는 함수
■ X(Feature 데이터) : 30개의 환자 데이터
■ Y(Label 데이터) : 0 음성(악성), 1 양성(정상)
confusion_matrix를 사용하여 test_Y에 대한 confusion matrix를 계산하여 cm에 저장하라.
답 :

실행 결과 :

실습 예제 2 – 정확도(Accuracy) 계산하기)
[실습1]의 결과를 바탕으로 분류 성능에 간단하면서도 중요한 정확도를 계산하여 모델의 성능을 판별하여라.
학습용 데이터와 평가용 데이터의 정확도를 계산하고 그 성능을 비교하라.
정확도 계산을 위한 사이킷런 함수/라이브러리 :
# train_X 데이터에 대한 정확도(accuracy) 값을 계산한다.
DTmodel.score(train_X, train_Y)
# 정확도를 구하는 함수
accuracy_score(Y_true, Y_pred)(Y_true,Y_pred는 각각 실제값과 예측값을 의미)
1. score를 사용하여 train_X에 대한 정확도를 계산하여 acc_train에 저장하라.
2. score를 사용하여 test_X에 대한 정확도를 계산하여 acc_test에 저장하라.
코드 :

실행 결과 :

실습 예제 3 – 정밀도(Precision), 재현율(Recall) 계산하기)
[실습2]의 결과를 바탕으로 분류 지표 중 정밀도와 재현율을 계산하여 모델의 성능을 판별해보아라.
학습용 데이터와 평가용 데이터의 정밀도와 재현율을 계산하고 그 성능을 비교하라.
정밀도와 재현율 계산을 위한 사이킷런 함수/라이브러리 :
# 학습용 데이터에 대한 정밀도(precision) 값을 계산한다.
precision_score(train_Y, y_pred_train)
# 학습용 데이터에 대한 재현율(recall) 값을 계산한다.
recall_score(train_Y, y_pred_train)
1. precision_score를 사용하여 학습용, 평가용 데이터에 대한 정밀도를 계산하여 precision_train, precision_test에 저장하라.
2. recall_score를 사용하여학습용, 평가용 데이터에 대한 재현율을 계산하여 recall_train, recall_test에 저장하라.
답 :

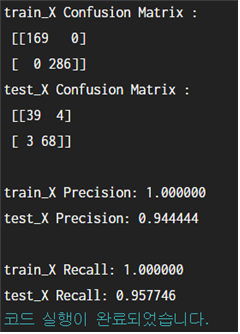
실행 결과 :
'인공지능 공부' 카테고리의 다른 글
| [2021 NIPA AI 교육 - 응용 / 딥러닝] 02 텐서플로우와 신경망 (0) | 2021.08.25 |
|---|---|
| [2021 NIPA AI 교육 - 응용 / 딥러닝] 01 퍼셉트론 (1) | 2021.08.24 |
| [2021 NIPA AI 교육 - 응용 / 머신러닝] 03 지도 학습 - 회귀 (0) | 2021.08.21 |
| [2021 NIPA AI 교육 - 응용 / 머신러닝] 02 데이터 전 처리하기 (1) | 2021.08.20 |
| [2021 NIPA AI 교육 - 응용 / 머신러닝] 01 자료 형태의 이해 (2) | 2021.08.19 |