이번 시간에는 머신러닝을 위한 데이터 전 처리를 이해해보도록 하겠다.
우선 머신러닝 과정을 이해할 필요가 있다.
이 머신러닝 과정은 크게 네 가지로 나눌 수 있다.

데이터를 수집하고 이 데이터들을 머신러닝 학습에 사용하기 전에 머신러닝에 사용할 수 있는 형태로 처리를 해줘야 하는데 이것을 데이터 분석 및 전 처리 과정이라고 한다.
마지막에는 평가를 하는데 잘 안되었다면 다시 학습하거나, 분석을 다시하거나, 새로운 데이터로 수집하거나 하는 전 단계 과정으로 돌아가게 된다.
그러면 대표적인 데이터 전 처리의 역할에 대해 보겠다.

크게 세 가지로 정리할 수 있는데,
첫 번째는 머신러닝의 입력 형태에 맞게 데이터를 변환한다는 것이다.
두 번째는 이상한 값들을 처리하는 데이터 정제의 역할이다.
세 번째는 아까봤던 머신러닝 과정에서 봤던 학습 단계와 평가 단계의 전용 데이터를 각각 준비하는 역할이다.
그럼 먼저 데이터 변환부터 살펴보겠다.

대부분의 머신러닝 모델은 숫자 데이터를 입력 받는데(특히 행렬 형태)(범주형 데이터도 수치형 데이터로 변환 가능)

실제 데이터들은 보통 머신러닝 모델이 이해할 수 없는 형태(행렬 형태가 아닌 형태)로 되어있기 때문이다.

그러므로 전 처리를 통해 머신러닝이 모델이 이해할 수 있는 형태로 바꿔줘야한다.
다음으로 데이터 정제가 왜 필요한지 알아보겠다.

표에서 보면 나이인데 값이 35.3으로 되어있다. 나이는 정수이므로 이는 이상치이고 이런 값을 지워야한다.
그리고 Cabin 열에 있는 데이터를 보면 NaN으로 값이 없는 데이터들이 있다. 이는 결측값이고 이것들 또한 없애줘야한다.
결측값이나 이상치가 있으면 머신러닝의 성능이 떨어지거나 아예 사용을 못할 수 있다. 따라서 데이터 정제가 필요하다.
마지막으로 데이터 분리가 필요한 이유에 대해 알아보겠다.

아까 본 것처럼 학습과 평가를 따로따로 하기 때문에 거기에 맞는 데이터가 각각 필요하다.
그래서 위와 같이 원본 데이터 150개가 있으면 학습용으로 100개, 평가용으로 50개를 따로 떼어서 분리해 사용한다.
근데 그냥 150개로 학습을 하면 안되는지 의문이 들 수 있다.
그 이유는 평가시 객관성이 떨어지기 때문이다.
지금까지 머신러닝을 위한 데이터 전 처리를 하는 이유에 대해 살펴보았고 대표적인 세 가지 기법에 대해 알아보았다.
뒤에서부터는 자료의 형태에 따라 어떤 전 처리를 하는지 알아보겠다.
먼저 범주형 자료 전 처리이다.
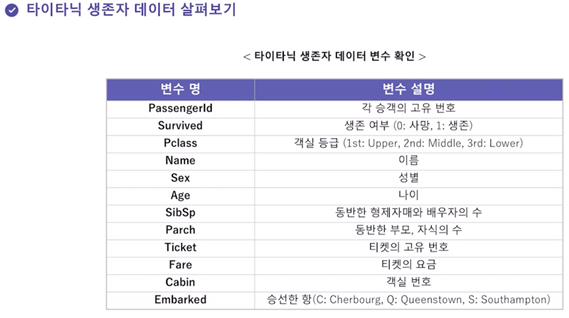
설명하기에 앞서 위와 같이 타이타닉 생존자 데이터가 있다고 하자.
이들을 가지고 범주형 자료를 살펴보겠다.

먼저 범주형 데이터는 빨간 박스로 둘러싸인 PassengerId, Survived, Pclass, Name, Sex, Ticket, Cabin, Embarked 이다.
(Name, PassengerId와 같은 데이터는 범주가 많은 형태의 범주형 자료라고 생각하면 된다.)
범주형 자료에는 두 가지 종류가 있다고 했다.

크기가 의미있는 순서형 자료는 Pclass 뿐이고 나머지는 다 명목형 자료이다.
그러면 이렇게 명목형 자료와 순서형 자료로 나눴을 때 어떻게 자료를 변환할지 자료 형태에 따라 알아보겠다.

대표적인 명목형 자료 변환 방식에는 수치 맵핑 방식과 더미(Dummy) 기법이 있고 순서형 자료 변환 방식에는 수치 맵핑 방식이 있다.
먼저 명목형 자료 변환에서 수치 맵핑 전환 방식이다.

범주에 해당하는 값을 0 또는 1과 같은 값으로 변환하는 것을 의미한다.
예시로 성별 자료를 male은 0, female은 1로 변환했다.
꼭 0, 1로만 해야하는 것은 아니고 (-1,1), (0, 100)과 같이 다양한 케이스가 있지만 모델에 따라 성능이 달라질 수 있다.

수치 맵핑 변환에서 위에서는 범주가 두 가지만 있었다. 만약 세 개 이상이라면 수치의 크기 간격을 같게 해 맵핑하면 된다.
마찬가지로 여기서도 맵핑하는 방식에 따라 성능이 달라질 수 있다.
다음으로는 더미 기법에 대해 알아보겠다.

더미 기법은 각 범주를 0 또는 1로 변환한다. 이렇게 보면 아까의 수치 맵핑과 비슷하다.
하지만 다른 점은 범주의 수에 따라 컬럼이 늘어났고(변수가 더 생김) 0은 그 컬럼에 대해 ‘아니다’라는 의미이고 1은 그 컬럼에 대해 ‘맞다’라는 의미이다. (즉, 모든 컬럼의 값이 1인 경우는 없다. 해당되는 컬럼만 1이다.)
예를 들자면 인덱스 0번째의 사람은 Sex_female이 0이고 Sex_male이 1이므로 남자이다.
다음으로는 순서형 자료 변환 방식인 수치 맵핑 변환에 대해 알아보겠다.

명목형 자료 변환에서의 수치 맵핑 변환과 비슷하게 수치에 맵핑해 변환하지만 수치 간 크기 차이는 커스텀이 가능하다는 차이점이 있다.
이 크기 차이에 따라 머신러닝 결과가 달라질 수 있다.
순서형 자료도 똑같은 크기 차이로 변환해도 상관은 없다. 하지만 위 예시처럼 매우 많음에 대해 강조를 하고 싶은 경우에는 크기 차이를 두면 된다.
실습 예제 1)
명목형 자료를 수치 맵핑 방식으로 변환해라
titanic 데이터에서 범주형 자료인 성별 데이터의 male, female 값을 각각 수치형 자료인 0과 1로 변환하라
(참고 :
DataFrame.replace({A:B, C:D,...})
는 A를 B로 C를 D로 변환하는 코드이다.)
답 :

실행 결과 :

실습 예제 2)
명목형 자료를 더미 방식으로 변환해라
(pandas의 DataFrame에서 이를 수행하기 위해서는 get_dummies()라는 함수를 사용한다.)
pd.get_dummies(DataFrame[[변수명]])
Embarked 컬럼의 S, Q, C 데이터를 더미를 사용해 변환하고 dummies 변수에 저장하라.
답 :

실행 결과 :

이번에는 수치형 자료 전 처리에 대해 알아보겠다.

먼저 수치형 자료는 크기를 갖는 수치형 값으로 이루어진 데이터로써 Age, SibSp, Parch, Fare 데이터들이 여기에 해당한다.
수치형 자료의 경우 머신러닝의 입력으로 바로 사용할 수 있지만 모델의 성능을 높이기 위해서 데이터 변환이 필요하다.
대표적인 수치형 자료 변환 방식으로는 아래와 같은 것들이 있다.

먼저 스케일링 방식부터 보겠다.

스케일링 방식이란 변수 값의 범위 및 크기를 변환하는 방식이다.
변수 간의 범위가 차이가 좀 나면 사용하는 것이 좋다.
이 스케일링 방식에는 대표적인 두 가지 방식이 있는데, 그 중에서 첫 번째로 정규화이다.
정규화는 변수 X를 정규화한 값을 X’라고 했을 때 위의 식과 같이 표현된다.
이 방식대로 변환을 하게 되면 변수 값의 범위가 0~100 이던 것이 0~1로 변환이 된다.
예시를 보겠다.

보면 feature_1과 feature_2는 값의 범위가 그렇게 크지 않다. 하지만 feature_3는 굉장히 큰 값들이 포함되어 범위가 크다. 만약 이대로 머신러닝에 들어가면 feature_3의 크기가 크기 때문에 feature_3의 영향을 많이 받게 된다.
그렇기 때문에 feature_3를 전 처리해주어 데이터 변환을 해줄 필요가 있다.
우측을 보면 정규화 변환을 통해 0과 1사이의 범주로 변환된 것을 볼 수 있다.
다음으로 두 번째 스케일링 방식의 두 번째 방식인 표준화를 보겠다.

통계공부를 해봤다면 많이 봤을 것이다.
어떤 분포가 정규분포를 따르고 있을 때 평균이 0, 표준편차가 1인 형태의 표준 정규 분포로 변환해주는 것이 표준화였다.
이것도 예시를 보겠다.

마찬가지로 feature_3의 값의 범위가 많이 줄어들었다.
표준화를 하게 되면 대체로 –2에서 2사이의 값들로 변환이 되게 된다.
마지막으로 범주화 방식에 대해 알아보겠다.

범주화는 변수의 값보다 범주가 중요한 경우에 사용한다.
예시를 하나 보겠다.
시험 점수와 관련된 10명의 데이터가 있다고 하자.
그리고 시험점수에 대해 예측하는 머신러닝을 만든다고 하자.
이 때 시험점수는 머신러닝에 바로 들어갈 수 있다. 하지만 머신러닝의 목표가 조금 바뀌어 시험점수 자체를 예측하는 것이 아니라 점수가 평균 이상일지 아닐지를 판별하는 머신러닝을 만든다고하자.
이런 경우에는 평균보다 높은지, 낮은지 ‘범주’를 예측하게 된다. 그랬을 때 이 시험점수 자체는 중요하지 않고 평균보다 높은지 낮은지에 대한 ‘범주’가 제일 중요한 정보가 될 것이다.
그래서 이런 경우에 범주화로 변환을 한다.
그랬을 때 변환하는 방식은 문제에 맞게 먼저 평균을 구하고 평균 이상은 1, 이하는 0으로 하여 데이터를 변환한다.
이 데이터를 가지고 머신러닝을 돌리면 평균보다 높은지 낮은지에 대해 예측할 수 있게 된다.
실습 예제)
titanic 데이터에서 수치형 자료인 Fare 데이터를 정규화해라
(참고 :

)
답 :

실행 결과 :

(추가 : 표준화를 수행하는 함수는 다음과 같이 구현하면 된다.

)
이제 마지막으로 데이터를 정제 및 분리하는 것에 대해 배워보겠다.
먼저 데이터 정제하기부터 배워보겠다.
데이터 정제하기에는 결측값 및 이상치 처리하기가 있었다.
거기서 결측값(Missing data) 처리하는 법부터 보겠다.

일반적인 입력값으로는 결측값을 사용할 수 없기 때문에 처리해줘야한다.
결측값을 처리하는 방식에는 크게 위의 세 가지 방식이 있다.
샘플 삭제는 결측값이 존재하는 행 자체를 삭제하는 방식이고, 변수 삭제는 해당 열 자체를 삭제하는 방식이다.
결측값을 다른 값으로 대체하는 경우에는 그 대체 값으로 1. 평균값, 2. 중앙값, 3. 머신러닝으로 예측한 값을 주로 많이 사용한다.
다음으로 이상치를 어떻게 처리하는지 보겠다.

이상치가 있으면 모델의 성능이 저하될 수 있기 때문에 일반적으로는 제거한다.
이상치를 판단하는 기준에는 위의 세 가지 방법이 있다.
이번에는 자세히 다루지는 않겠지만 통계에는 굉장히 여러 가지 지표가 있고 그 지표를 통해서 그 지표보다 크거나 작을 때 이상치라고 판단할 수 있는 방법들이 있다. (카이제곱 검정, IQR 지표)
그리고 눈으로 보고 직접 판단하는 방법도 있다. 마지막으로 전처리 과정에서도 새로운 머신러닝을 사용해 분류하는 방법도 있다.
이제 마지막으로 데이터 분리하기에 대해 살펴보겠다.
데이터 분리는 왜 필요할까?

머신러닝 모델을 평가하기 위해서는 학습에 사용하지 않은 평가용 데이터가 필요하다.
아까 살펴본 머신러닝 과정에서 3번째에는 학습, 4번째는 평가였다.
이에 사용할 데이터를 약 7:3에서 8:2 비율로 분리한다.
학습용 데이터, 평가용 데이터 분리하기 이후에 지도학습의 경우 한 가지 데이터 분리를 더 해야한다. 지도학습의 경우 feature 데이터와 label 데이터가 분리된다.

예를 들어 공부시간 데이터와 시험점수 데이터가 들어온다고 할 때, 머신러닝으로 공부시간 대비 시험점수를 예측한다고 하자.
이 때, 시험점수는 예측해야 할 대상이 되는 데이터로 Label 데이터이고 공부시간은 Label 데이터인 시험점수를 예측하기 위한 입력 값인 Feature 데이터이다.
한 가지 예시를 더 보겠다.

이 경우 Survived이 label 데이터가 된다. 그리고 나머지 데이터들이 feature 데이터이다.
이렇게 지도학습에서는 이 두 가지 데이터를 추가로 분리해야한다.
실습 예제 1-1)
titanic 데이터에서 과반수 이상의 데이터가 결측값으로 존재하는 Cabin 변수를 삭제하라. 이 후, 나머지 변수에 존재하는 결측값을 처리하기 위하여 결측값이 존재하는 샘플들을 제거하라.
참고 :
pandas의 DataFrame에서 특정 변수(columns)를 삭제하기 위해서는 drop() 함수를 사용
DataFrame.drop(columns=[변수명])
DataFrame에서 결측값이 있는 샘플을 제거하기 위해서는 dropna() 함수를 사용
DataFrame.dropna()
실습 예제 1-2)
titanic 데이터에서 Age 변수에 존재하는 이상치를 제거하라. (Age 변수안의 소수점으로 표현되는 데이터를 제거)
답 :

실습 예제 2)
titanic 데이터에서 생존 여부인 Survived 을 예측하는 머신러닝을 수행한다고 했을 때 데이터를 분리하라. 앞서 한 실습 예제에서 이상치 처리한 데이터를 바탕으로 feature 데이터와 label 데이터를 분리한다. 이 후 학습용, 평가용 데이터로 분리한다.
참고 :
학습용, 평가용 데이터 분리는 sklearn 라이브러리의 train_test_split() 함수를 사용하여 분리할 수 있다.
X_train, X_test, y_train, y_test = train_test_split(feature 데이터, label 데이터, test_size= 0~1 값, random_state=랜덤시드값)
1. titanic_3 에서 Survived 변수를 제거하여 X에 저장하고 Survived 변수의 데이터는 pandas의 Series 형태로 y에 저장하라.
2. train_test_split 를 사용하여 데이터를 분리한다. test_size는 0.3, random_state는 42로 설정한다.
답 :

실행 결과 :

'인공지능 공부' 카테고리의 다른 글
| [2021 NIPA AI 교육 - 응용 / 머신러닝] 04 지도 학습 - 분류 (0) | 2021.08.22 |
|---|---|
| [2021 NIPA AI 교육 - 응용 / 머신러닝] 03 지도 학습 - 회귀 (0) | 2021.08.21 |
| [2021 NIPA AI 교육 - 응용 / 머신러닝] 01 자료 형태의 이해 (2) | 2021.08.19 |
| [2021 NIPA AI 교육 - 응용 / 머신러닝] 00 인공지능/머신러닝 개론 (2) | 2021.08.19 |
| [2021 NIPA AI 교육 - 기본] 05 Matplotlib 데이터 시각화 (0) | 2021.08.11 |